k8s容器内部应用向eruaka注册ip问题
本文共 1190 字,大约阅读时间需要 3 分钟。
springboot项目部署到k8s中,发现eruaka注册是容器id,这个其他应用是无法访问的
 参考,现在
参考,现在pom.xml中添加: org.springframework.cloud spring-cloud-commons
接着使用${spring.cloud.client.ip-address}
eureka: instance: instance-id: ${ spring.cloud.client.ip-address}: preferIpAddress: true statusPageUrlPath: /actuator/info healthCheckUrlPath: /actuator/health client: service-url: defaultZone: http://192.168.5.207:8761/eureka/,http://192.168.5.180:8761/eureka/,http://192.168.5.154:8761/eureka/ 确实替换为id了,但是确实容器IP,并不是主机IP,外部还是无法访问.
 在k8s中设置
在k8s中设置spring.cloud.client.ip-address和k8s.port的环境变量, 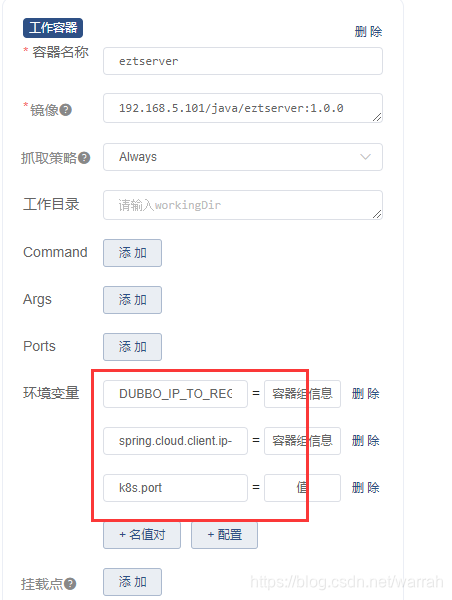 在eruaka中看似是对的,点击链接打开的还是
在eruaka中看似是对的,点击链接打开的还是http://179.20.3.178:9010/actuator/info,依旧是容器ip和端口, 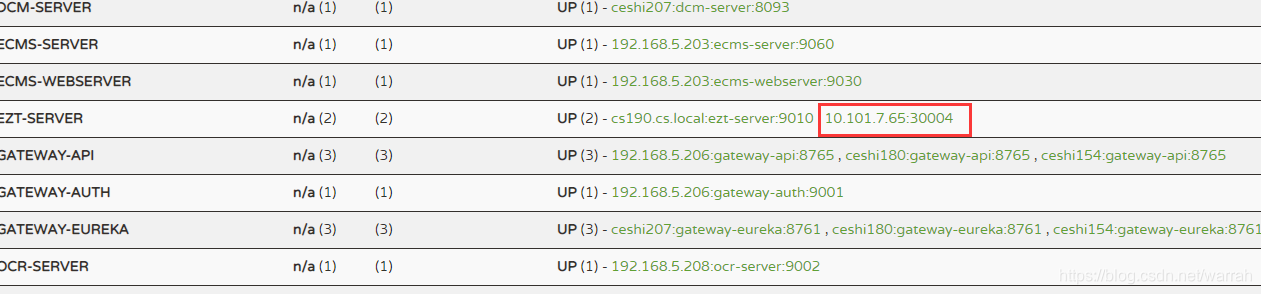 然而使用使用主机的IP和端口却可以访问.
然而使用使用主机的IP和端口却可以访问. 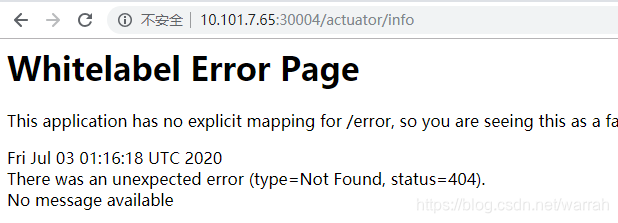 这两者之前的不一致问题,怎么解决呢?如果了解k8s的网络模式,,解决办法就知道了。设置
这两者之前的不一致问题,怎么解决呢?如果了解k8s的网络模式,,解决办法就知道了。设置hostNetwork: true问题就解决了。就不用什么instance-id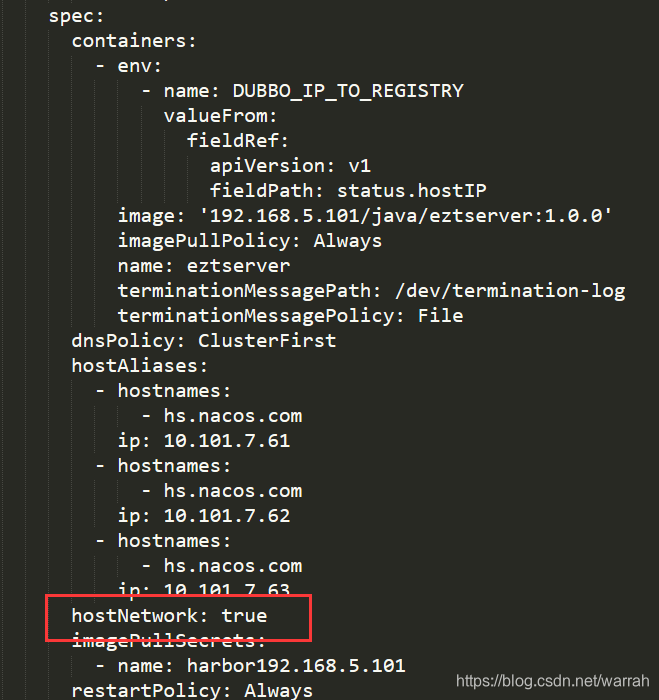 再看eruaka,就可以正常访问了
再看eruaka,就可以正常访问了 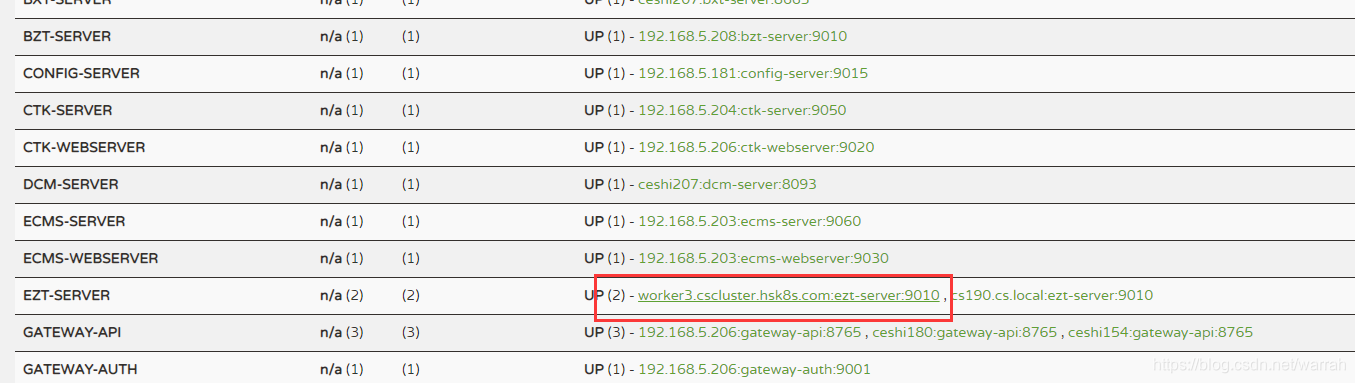 使用
使用hostNetwork有弊端,会出现端口占用,故这里推荐使用下图的方式,使用EUREKA_INSTANCE_IP-ADDRESS环境变量即可,处理方式跟一致 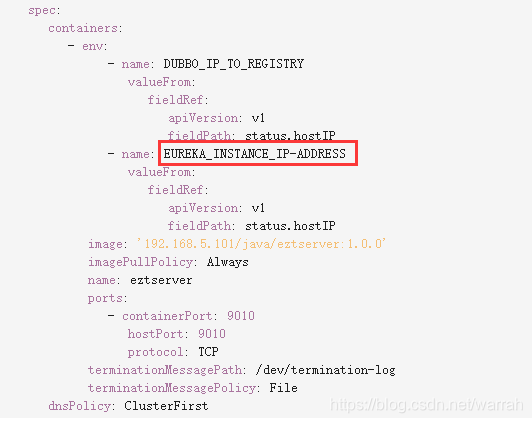 当系统部署到生产环境,这里还有个dns的问题,你会发现docker内部无法访问域名
当系统部署到生产环境,这里还有个dns的问题,你会发现docker内部无法访问域名 dnsConfig: nameservers: - 223.5.5.5```
转载地址:http://ktwo.baihongyu.com/
你可能感兴趣的文章
mysql 数据库备份及ibdata1的瘦身
查看>>
MySQL 数据库备份种类以及常用备份工具汇总
查看>>
mysql 数据库存储引擎怎么选择?快来看看性能测试吧
查看>>
MySQL 数据库操作指南:学习如何使用 Python 进行增删改查操作
查看>>
MySQL 数据库的高可用性分析
查看>>
MySQL 数据库设计总结
查看>>
Mysql 数据库重置ID排序
查看>>
Mysql 数据类型一日期
查看>>
MySQL 数据类型和属性
查看>>
mysql 敲错命令 想取消怎么办?
查看>>
Mysql 整形列的字节与存储范围
查看>>
mysql 断电数据损坏,无法启动
查看>>
MySQL 日期时间类型的选择
查看>>
Mysql 时间操作(当天,昨天,7天,30天,半年,全年,季度)
查看>>
MySQL 是如何加锁的?
查看>>
MySQL 是怎样运行的 - InnoDB数据页结构
查看>>
mysql 更新子表_mysql 在update中实现子查询的方式
查看>>
MySQL 有什么优点?
查看>>
mysql 权限整理记录
查看>>
mysql 权限登录问题:ERROR 1045 (28000): Access denied for user ‘root‘@‘localhost‘ (using password: YES)
查看>>